
So over the weekend, there were some good questions from my coworker Ami's husband, so I thought I would publish them in a kinda FAQ/rant way, hoping that it will benefit more people to understand the inner workings of BranchCache and how it integrates with file de-duplication that was incorporated in Windows Server 2012. Enjoy.
Question: For a ConfigMgr Distribution Point (DP), unless using dedup, is it enough to run the Publish-BCWebContent cmdlet, pointing to the content library to have the DP pre-calculate all the hashes (CI’s) needed for ConfigMgr content?
Answer: Pre-creation is never really required, but can improve the peer-to-peer results depending on how things are deployed and client versions. But to answer this question, yes that is enough. The question you really want to ask is;
How does Windows 7 and above deal when the hash is not pre-created on the server?
We will answer this key question further down in this post, but first lets warm up with some questions on how the hashing works, and how it interacts with file de-duplication.
Question: If I need hashes pre-created for both W7 and W10 clients, do I need to run Publish-BCWebContent twice on the server, with 1 and 2 values for the -UseVersion parameter?
Answer: Yes, without the param, it will generate only for the version that the system is configured for (if memory serves me right).
Question: What CI version will the server generate hashes for when using dedup on the DP? Only for Windows 10 clients?
Answer: Short answer, file DeDupe will only help with V2 hashing (W8 and W10). Long answer: The file storage dedupe will only store the file hash data, i.e. a Hash of Data (HoD). BC still needs to generate the HoDk for the CI, (HoD = hash of data + server secret key (hashed) = HoDk)… then the client hash that, which gives us a Hash of (Hash of Data + Key) = HoHoDk. But the two later parts of the hashing is ‘hellovalot’ less CPU demanding than the file hash. The server calculates the HoD + K calculation and the HoHoDk is actually calculated by the client, not the server. Why are the later two hashing parts are faster? Reason being that the hash is small, 32 bytes + server secret and the file data is much larger. Think of it like putting a pre-made pizza in the micro compared to cooking from scratch.
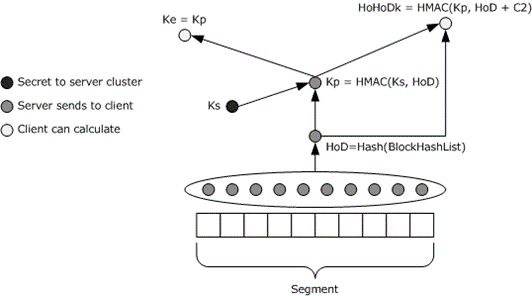
Laymen terms for above diagram:
HoD = Segment hash
Ks = Server secret
Kp = Segment hash with server secret = Segment secret = HMAC(Server Secret, HoD)
HMAC = The hashing algorithm is assumed to take an arbitrary-length byte string as input, and to output a fixed-length binary string as output.
Basically the beauty is that the client can decrypt the data without knowing the server secret. The exact flow can be seen here: https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-pccrc/2f508e77-be57-4862-9d56-78516ec93448
Question: And what if I wanted to prestage content in the BC cache on a client, files that are locally on the client already, for example in the CM cache. Can I just run the InjectBCData.ps1 script that you wrote (that runs BranchCacheTool.exe), specifying the local older?
Answer: Yes, there will be a new version of that coming soon, Phil has the latest we use at customers. Separate blog coming from Phil on this. The script that we are referring to is a script that can inject any data structure into BranchCache with some clever logic attached to it.
Question: And do I need to run the script with the server secret from the DP? Or no server secret?
Answer: Yes, otherwise the HoDk’s wont match and the HoHoDk’s end up being wrong, i.e. data requested wont match. Don’t forget to change the secret back once the data is migrated.
Question: I would like your thoughts regarding precaching efficiency, if a client have plenty of disk, and you want to pre-caching content for BranchCache, would you download to the CM Cache, to make sure all files are there for the client, and then stage most of that in the BC cache (e.g. all but the smaller files)?
Answer: Best is to not have small files in packages, period. Easiest is to cache all of it. Best/fastest is to cache a single .zip. But really, what you want to ask is: “How do I effectively pre-cache with BranchCache?”
Question: Or would you only prestage in the BC cache, and the client would have to go to a DP (or Peer Cache source) for smaller files?
Answer: Cache all in BC cache, but keep number of files low and not small.
Question: I did read your post about small files: https://twopint.wpengine.com/branchcache-teeny-weeny-files/ Is the MinContentLength something you configure on each client, or on the server (DP)?
Answer: You configure it only on the server, so for a Management Point if makes more sense than on a DP, but it also adds to a BC DB bloat. Some customers use it to get the st0pid large driver packages cached, but .zip them is a far better solution.
Question: Have you done any large scale tests with small values, like 4kb or 8kb?
Answer: Yes, it works well, but the BranchCache database overhead is huge when caching 4kb files, both client side and server side. So it's better to change the way you distribute content.
Question: When doing the training labs, I’m pretty sure Mr. Phil recommended we add dedup (or precache), to guarantee that BC worked with only a few clients.... Do you always add DeDup to your customers DP’s? Or recommend it?
Answer: Yeah, so we normally always recommend DeDupe, it just makes sense from a storing perspective, but why do we push it?? I think why we recommended it in the lab, is to ensure that we have the hashes available, which goes back to the question:
“How does Windows 7 and above deal when the hash is not pre-created on the server?”
This question is complex, and involves some bad stuff and customer always gets this messed up in a lab. In a perfect world, the logic should be;
- First machine comes in, asks for hash to be generated, but downloads without it, getting 0 in BC cache as hashes were not available.
- Second machine comes in, gets 0 from p2p, as first didn’t have it it’s cache. Second machine now has it.
- Third machine comes in, gets all from cache.
Above is not what happens though, when people try it out, instead the following normally happens:
- Customer runs first download on gigabit, it takes 2 sec to download package
- Customer runs second and third download on the other machines in parallel, 5 seconds after first completed, server has not generated hashed yet, so it downloads without it, in 2 sec.
- Customer either says that BranchCache is shit and uninstalls, or hits all GPO’s possible and breaks stuff.
So why does this happen, and how does the client server interoperability work? Well, this is a great question, so lets break it down: The client connects, and says it can do peerdist, and the server responds that it can do BC, but does not have hashes available, but that it can generate them if requested, so far so good. Both 7 and 10 will instruct the server to do so, but then there is a difference...
- On a Windows 7 client, BITS will never retry BranchCache if the server didn’t have the hash at the start of the file.
- A Windows 10 client however, will retry BranchCache for each range (data chunk) of a single file that BITS downloads.
In reality though, this has mixed effects depending on how admins deal with stuff. In a lab, a customer pushed a 2GB package to 10 clients at the same time, i.e. at 10.00AM. All clients which is on gigabit network, will download the content before the server has generated the hash, resulting in 0% BC. In a WAN scenario with V2 clients, i.e. 8 and above, the slowness of the pulling clients will allow the server time to generate the hashes, giving pretty good p2p story, even if the hashes were not generated before clients started download.
Doing the same with Windows 7 can totally kill your BC results, because it’s likely that the server wont have time to generate any hashes, and the Windows 7 clients never retries BC if the hash is missing, equaling to a total failure of peer-to-peer. Luckily this sort of nonsense doesn’t happen with V2.
The Windows 7 scenario above does of course depend on file sizes, number of files, execution times etc. The behaviour for foreground jobs (Software Center) and pushed from console, are different as well, where foreground jobs have very different retry pattern (favours speed over p2p effectiveness) as the rest of the BITS priorities. But at 2Pint Software we have seen boatloads of bytes being ‘slow boated over the WAN’, not peer-to-peering, due to administrators not understanding how BranchCache works. This is also one of the major reasons we build our StifleR product, as we remove this entire problem.
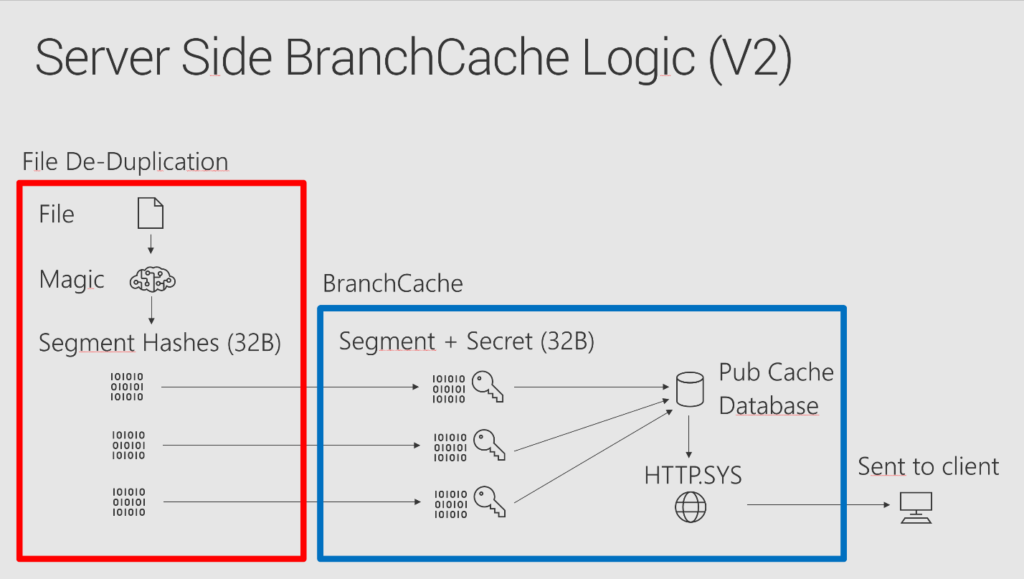
But when doing work with BranchCache in the lab without our products, we thought it would be better to generate the hashes with DeDupe first, and just tell people to do that properly. But evidence shows that customers have a hard time grasping this and getting it right, so we are back to do drawing board at this point and plan to support not only the hash generation but also verification, for all content via StifleR. The following diagram shows how file deduplication helps with BranchCache. When using file de-duplication, the file server will take care of the red part, which is the CPU intensive part, BranchCache then only deals with the blue part. That way, it's fast to respond to clients and can reply fast when the clients request content. If you don't use file level de-duplication, BranchCache on the server side does both the red and the blue parts, which makes the reply slow.
The server can generate hashes on the fly and feed to clients, but only when the pulling speed is about 10Mb/s (depending on server HW). You can see that from this graph that is from Andreas Hammarskjölds Ignite 2016 presentation:
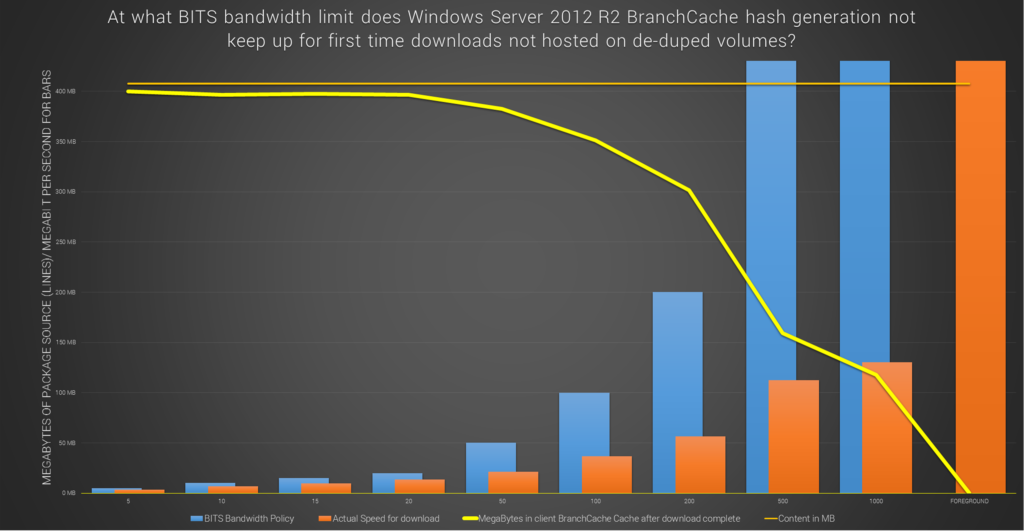
When DeDupe has the file hashes, typically the server can respond with the hash at much higher rates (1GB) depending on file size, cpu etc. DeDupe FTW!
Question: What is the best form of package to ensure maximum peer-to-peer speed and download efficiency?
Answer: In single ‘loosely’ compressed format like MS .zip or FAST compressed .wim’s etc.
Bonus Question: What is really inside a Content Identifier?
Answer: Short answer; Magic. Long answer; In order to improve the peer-to-peer and caching for BranchCache, content is divided into one or more segments. For Version 1 (Windows 7) each segment is a binary string of a standard size (32 megabytes), except the last segment, which might be smaller if the content size is not a multiple of the standard segment size.
In version 2.0 Content Information, segments can vary in size. Each segment is requested and identified on the network by its segment ID, also known as HoHoDk. Different content items can share the same segment if they happen to contain an identical part that coincides with a complete segment. This is what makes BranchCache “de-duplication aware”, and why version 2 of BranchCache rocks. Content Information includes only the list of block hashes, the HoD, and Kp. Ke and HoHoDk are not included in Content Information. A peer receiving the Content Information derives them from the available values according to the formulae later in this section. Ks = Server secret is never disclosed by the server.
In version 1.0 Content Information, each segment is divided in turn into blocks. Each block is a binary string of a fixed size (64 kilobytes), except for the last block in the last segment, which again might be shorter. Unlike segments, blocks in different segments are treated as distinct objects, even if identical. Blocks within a segment are identified by their progressive index within the segment (Block 0 is the first block in the segment, Block 1 the second, and so on). Because of the fixed block size, a block's index can also be used to compute its actual byte offset in the segment. Given the standard block size of 64 kilobytes, Block 0 is located at offset 0 in the segment, Block 1 at offset 65536, Block 2 at offset 131072, etc.
For Content Information version 2.0, Kp, Ke, and HoHoDk are calculated in the same way as in Content Information version 1.0. However, there are no blocks or block hashes in Content Information version 2.0. The segment HoD is calculated as the hash of the content segment.
Note that given the entire set of blocks for a segment, each identified by index, one can reconstruct the original segment simply by concatenating the blocks in order by index. Similarly, given the entire sequence of HoHoDk values for the successive segments in a content item, and a set of segments with matching associated HoHoDk values, one can reconstruct the original content simply by concatenating the segments in order based on HoHoDk values. If you are keen to know more about this kind of stuff, please attend the BranchCache, Deep Dive in Margarita Land for Large Enterprises - 500 level at the Midwest Management Summit in May!
//Andreas
PS. There will one upcoming blog on how StifleR deals with Pre-Caching in the 2.0 version, understanding the above is a pre-req for that post.
PSS. There will be one upcoming blog on how StifleR deals with BranchCache Cache reporting, and all of the above is pre-req for understanding that.
Top Posts
2Pint Software blog roundup - spring 2026 edition
2Pint Software welcomes Nathan Ziehnert to the team!
2Pint Software welcomes Christian I. Nilsson to the team!

By David Meurer

By Andreas Hammarskjöld

By Andreas Hammarskjöld
By David Meurer