
We are always trying to simplify the anatomy of a BranchCache job so that IT pros can implement it with confidence knowing how it works.
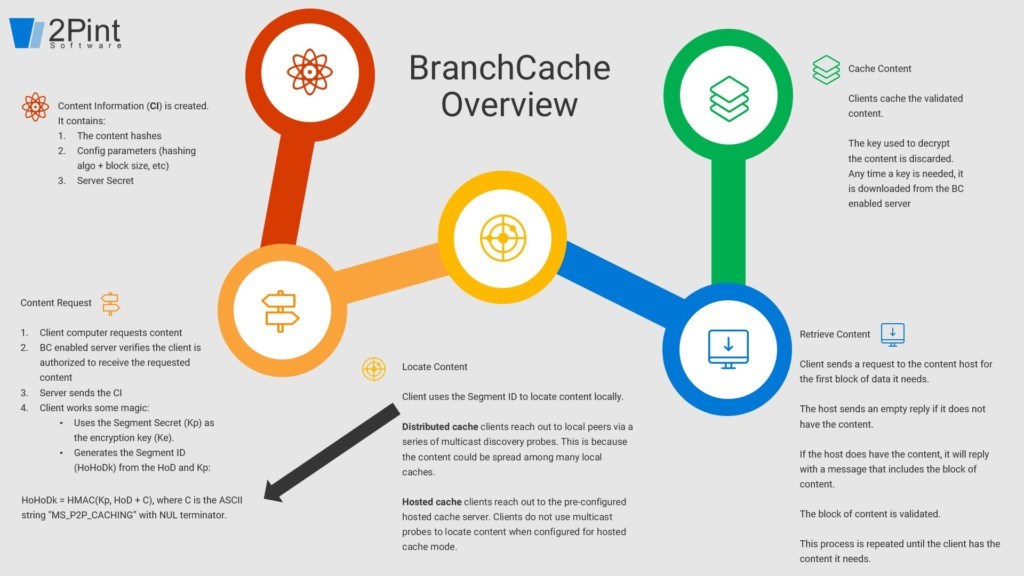
A picture is worth a thousand words, but fortunately for all of us there aren't that many on this infographic.
Basics of a BranchCache Job:
- Request – a client initiates a job by requesting content from the server. The server will check to see if the client is authorized to get the content. If both server and client are BC enabled, the server will generate the content metadata (the hash, CI, segment ID, etc.). The hash generation can be done before the request by enabling and running data deduplication on the content library on the server. The content metadata gives the client enough info to locate the client on the local network before it tries to download over a WAN.
- Locate – Now the client needs to search locally for the content by using the hash for the content it got from the server. It will first check its own cache which is separate from the ConfigMgr cache. If it finds the content in its own local cache, it won’t look anywhere else. If the content is not in its own local cache it will start to look at local peers who might have it. If nobody has it locally, it will go back to the server to request it.
- Retrieve – Taking a few steps back, the actual data is encrypted by the server when it divides the content into segments and then subdivides the segments into blocks. The content hash is sent on the same channel as the actual content. Also, each server is configured with a secret key. All of this prevents brute force attacks. The client can trust the source of the data. You can walk through this process using our HashiBashi tool.
- Cache – clients save the content in their cache, and the hash it downloaded first ensures the client doesn’t download anything that’s not associated with the content in question. Meaning if a source tried to send malicious content, it would get dropped because of a hash mismatch. To serve it to another client they need to check for a match in hashes in future probe messages. A client isn’t going to also cache hashes, the server does that.
Difference between hosted cache and distributed cache modes
Distributed – no real need for DP at location. Discovery of content in DC mode is done on the WS-Discovery protocol. The protocol works like this: a one-way multicast hello, a bi-directional probe with the first probe being multicast and the probe match being unicast, a bi-directional resolve following the same multicast then unicast pattern, and a one-way multicast goodbye. Good trivia information if you ever find yourself on a BranchCache gameshow. Also good for troubleshooting.
Hosted – kind of like a DP. The clients are hard-coded with a server at the location to go to that has the content in question. The clients communicate directly with the server in this scenario so there is no discovery required. As we work to test hosted cache mode in more enterprise environments we are starting to think it might also be a suitable replacement for distributed cache mode in scenarios where the networking team might be blocking multicast discovery on wireless routers.
Can I do some monitoring?
Of course you can. We have StifleR as well as a read-only (and free) version called StifleR Visualizer. We think it's the bee's knees and aren't ashamed of our bias. You can also use other tools such as Wireshark, good old Microsoft Message Analyzer. Windows itself provides simple options as well. Basic monitoring can be done using Perf mon and looking at BranchCache performance stats. It doesn’t always update in exact real-time, so you can get better information looking in the BITS Client event log in good old event log on the local computer. Zooming in to ID 60, you can see whether the download tried to use BranchCache, and how much of the content came from peers. Since a single file can have multiple hashes that comprise the whole file, the download can come from multiple sources.
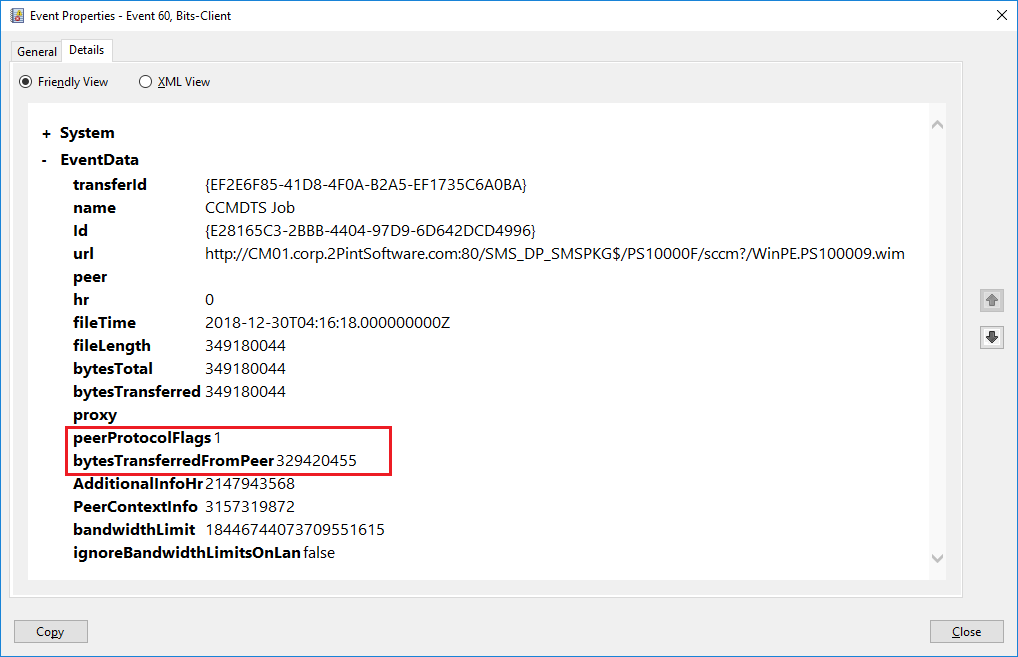
peerProtocolFlags 0 – no BranchCache
peerProtofolFlags 1 – downloaded via BranchCache
bytesTransferredFromPeer – shows at the byte level how much of the file came from a peer. The higher the number, the better if you’re wanting BranchCache efficiency.
If you’re looking for more geeky BranchCache content, be sure to check out our other blog posts. You can also catch up on old presentations from Ignite on Channel 9.

By David Meurer

By Michael Niehaus

By Michael Niehaus

By Michael Niehaus