

One of the things that comes into play when doing any P2P stuff with BranchCache is the odd speed that you always seems to get. The same type of machine seems to almost always get the same speed, so what is up with that? The speed seems locked at around 30-80Mbs depending on hardware. When doing regular mass deployments, this is typically not an issue, it's actually more of a feature, as the speed is per machine, and the memory and CPU utilization on the hardware is more or less not noticeable, but when doing OS Deployments, speed is key. What can be done about it? Well, there are several things we can do, but lets start by looking into what causes this "slow" speed to begin with.
Background - Being slow is a feature
BITS (which is the workhorse here) is designed to have different priorities of content, LOW, NORMAL, HIGH, and FOREGROUND. The LOW, NORMAL, and HIGH is pretty easy to understand. It means that if we only have a LOW job, and a NORMAL job comes along, it will process that first. If you have two NORMAL jobs, it will round-robin them until they are all complete. Easy peasy!
LOW-HIGH are also jobs that are affected by BITS throttling policy, and if you are a poor soul that cant use 2Pint's StifleR solution to manage this, you can set different throttles per job type. When it comes to BITS and BranchCache, it all works the same. The job will request the first block of data for several seconds (hence why BITS jobs with no P2P can take a long time to start. It does this to see if anyone else is downloading the same content, in order to force a "flash crowd" scenario download that sets longer timeouts in order to favor WAN offloading. Excellent!! If content is then missing, it will retry the same content at several intervals during the download, before giving up when the timeout is exceeded.
FOREGROUND jobs do things differently. They does not broadcast the same ID several times, it just starts to dig in and fetch data. It also doesn't retry as much as the other job priorities, so we get higher speeds. Also, FOREGROUND jobs do not use ANY throttling from the BITS policy, so things are free for all. Also, you can have several FOREGROUND jobs on the same client, meanwhile all the other jobs are only one job at a time. You can still use 2Pint StifleR and LEDBAT++ to throttle BITS (but that is whole different concept and is really a whole new blog series).
So with this knowledge, lets try to figure out why things are slow; imagine the following events which need to happen during a BranchCache-enable BITS download:
- Allocate buffer for X size (for a block of data)
- Send out x messages to find content from peers
- Wait for timeout or reply
- Get the data from the peers replying
- Fill the buffers (BranchCache has to complete the whole thing before decrypting and validating) the actual data.
- Decrypt & verify
- Rinse and repeat and move further down the file
Sure, we can do X number of these at the same time, but cant do too many, as that would consume every core in the machine until the download is complete, basically pegging at 100% CPU.
As a side rant, here is some information from an exchange with the MS BranchCache devs from 6 years ago when we looked into the effectiveness of the BranchCache protocol:
Question:
Why on earth did you (Microsoft) put the IV after the data in the peer content retrieval? Then we can’t decrypt as we retrieve data, instead have to write to cache and then revisit to do the decrypt. Very inefficient. Just “didn’t think of that” or a “RAM is cheap” or is there a reason for this madness?
Answer:
Good point. This is something that I overlooked, I’d say probably because an in-line decryption was never needed in our implementation, as we handle blocks buffered in memory and atomically served between layers.
From a protocol point of view you have a point, the IV data in front would have made more sense, since the way it is now prevents in-line decryption.
I wouldn’t say very inefficient though. Blocks are not written and read back for decryption. They are surfaced across layers atomically, decrypted in a single shot and validated on the fly (atomicity here minimizes context switch), and surfaced to the data stream (which is the high priority path), while low-pri/asynchronously written down from the original encrypted buffer. Keep in mind that we cannot serve data to the application until it is validated, and validation can be performed only once the full block is available and decrypted, so block-size buffering is needed anyway.
A bit more memory-expensive approach, but quite efficient for the size of blocks that we are dealing with (<= 128kb).
So what does determine the speed then?
The following few little golden nuggets determine the total max speed of BranchCache:
- Faster CPU's
- Number of files - each file deals with new IO internals in BITS and the OS (like HTTPS calls etc.)
- Each new file is a new Content Information structure, which means lots of new API calls etc. Keeping it within the same file, we increase the speed.
- Set the BITS jobs to FOREGROUND
- BranchCache buffer size - larger buffer allows for lots of more data before to be handled on the wire
- BranchCache timeouts - as we set large buffers, we will drive super high CPU (as we drive much higher rates) so some messages will timeout unless we set high timeouts
So what can we do?
- We can adjust 1, lets all buy i9 processors. Right. 😂🤣
- We can adjust 2, we have been blogging about this, there is good reason for these blogs, but you will have to do some work.
So by doing these two changes, you can kind of get around 200Mb/s on modern hardware, which isn't too bad. Sometimes faster downloads, mostly because BranchCache finds duplicates in its own file. The following picture shows where the BITS jobs finds local content and doesn't have to query the network, peaking the speed to above 300Mb:
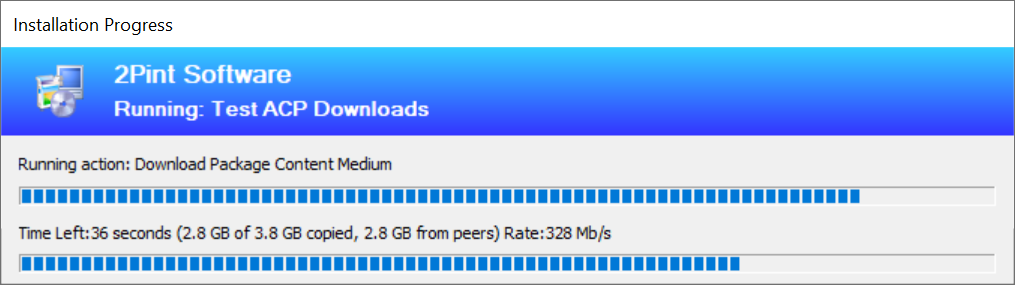
But it isn't too fast either. Then we cant really change much without going outside the whole process. Enter 2Pint Software OSD Toolkit Turbo mode!
The OSD Toolkit Turbo
As BITS does not allow to set the buffer size that is used for BranchCache it will never allow us to drive the speeds we are after. So, we need to go outside the process. So we engineered a new way for the BITSACP to drive higher speeds, giving us close to line wire speeds on faster CPU's and double/tripling/quadrupling the speed on slower CPU's.
But the speed comes at a price, it drives CPU usage to an absolute maximum also, with a rather large memory consumption on top. The thought process behind this, is that if there is an TS that is actively running, we want to complete it as fast as possible. Even if it's an IPU Task Sequence the user will usually be away from the machine while it runs. We also drive higher CPU from the machines we are pulling from, but not even closely to as high as the machine we are pulling to.
The Price of Speed
This new shiny feature was a lot of work and has a lot of moving parts, and since 99% of the people that use OSD Toolkit dont pay support for it, we decided to only give this feature to customers that have a paid support agreement with us. Call us mean, but we have to pay the bills somehow.. And support for OSD Toolkit is a very low cost, so you will save money by buying it, as it will save your technicians a lot of time staring at progress bars. You can call it sanity insurance if you want to.
So how does it work?
Basically, the internals are somewhat complicated, but the BITSACP.EXE will review the list of files in the content it downloads, then it takes the 5 largest files (if they are over 50MB) and calls the BranchCache API directly, with bloated 64MB buffer sizes. If they are all downloaded OK, we use them and then transfer any remaining files using the good old BITS job that will then run at FOREGROUND priority to get any remaining files.
So the Golden Rules to Superspeed are:
- Single file in the package (not a 1GB + one tiny text file, although the small file will be the only file that is fetched using BITS).
- Single file in the package.
- Single file in the package. Got it? Good!
- Don't test with slow virtual CPU's, a single CPU VM at 2.1Ghz will be slow compared to a single VM with 100% CPU allocation on a 4.6Ghz device.
- 100% of the content has to be pre-cached to any other machine in the same location. Remember, we are only speeding up the P2P transfer, not the speed from DP. (That can be increased as well but that is another blog coming soon).
What kind of speeds can I expect?
So we speed up file fetches greatly when pulling from caches, both locally and external peers. So for remote peers, it also depends a little on the state of the remote peers. As an example, speeds on an i7 at 4.5Ghz will pull from other peers at around 500-600 Mb/s. If the other peers are busy, it will slow down the Turbo. For a slow 2.1Ghz virtual machine, we get around 250Mb/s as compared to around 50-60 Mb/s without Turbo. So you get more and more Turbo the faster your CPU is.
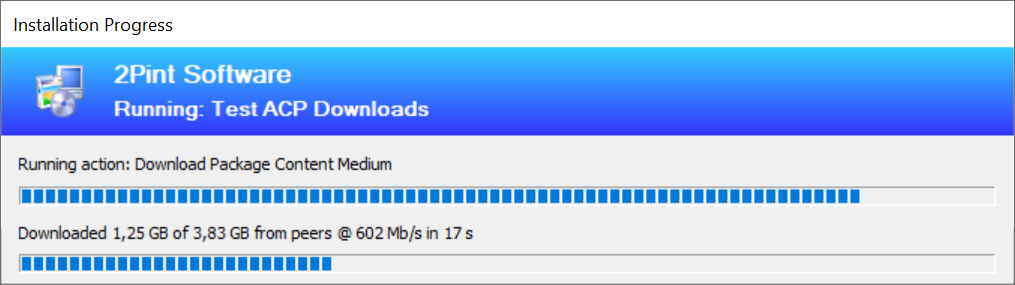
When pulling content out of your local cache (Well hello IPU content!!) you can expect speed at around 5000 Mb/s, yes, that is five thousand megabits per second. (If your disk can cope with these speeds!)
How do I enable it?
First of all, you need the latest and greatest OSD Toolkit.
Secondly, you need a license key to put in as a TS Environment variable, the binaries then read this and enables it automatically.
How can I tell it's working?
Easiest way to tell is that the progress bar is slightly different when the machine is revving the Turbo, first of all, we spend a little bit longer on this progressbar (depending on file size) because we have to download the Content Information again:
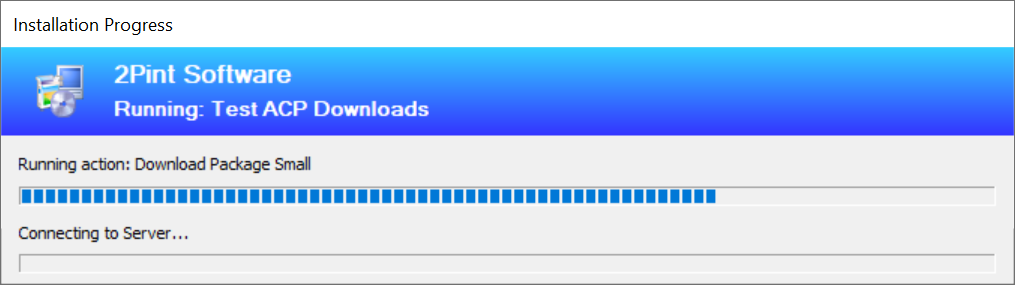
Then once that is done, we start pulling down the bits as fast as we can:
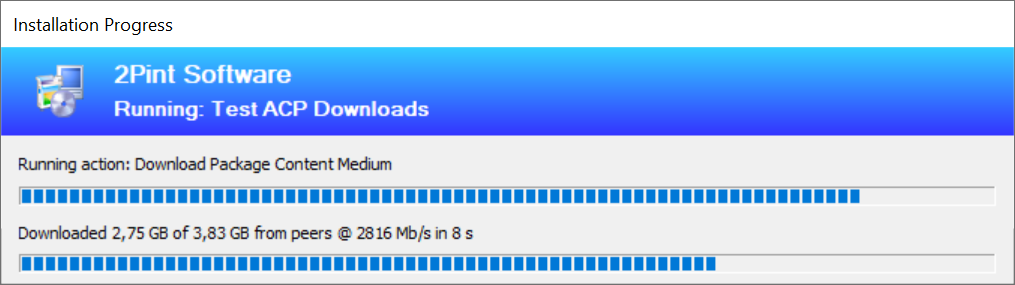
In the picture above, you can see the wording "Downloaded 2.75GB of 3.83GB from peers", which means all of it is Turboing, in this case, hence the speed, all coming from the local cache. The picture below shows the different progress when BITS (No Turbo) is running:
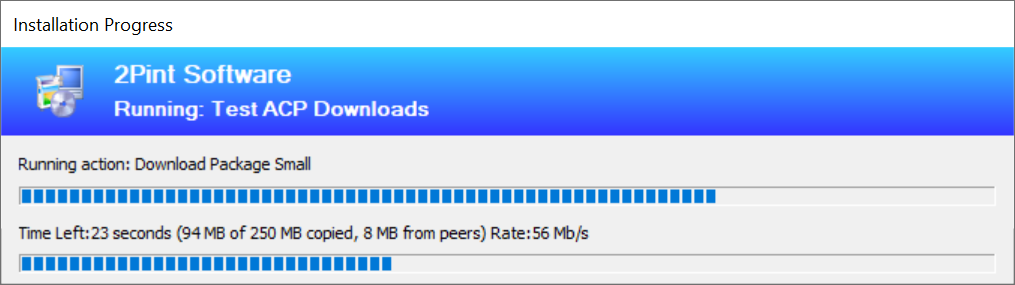
What happens when the Turbo breaks down?
If the Turbo breaks down, the regular BITS job will take over and get the files down. Any previously cached content will be quickly recovered from the local cache, and then written to the download. The following two pictures show that concept, first one showing the recovering phase where speed is very high pulling from local cache. First one showing recovering at 940Mb/s, note the progressbar has the start of "Time left" which means its the BITS job doing the transfer:
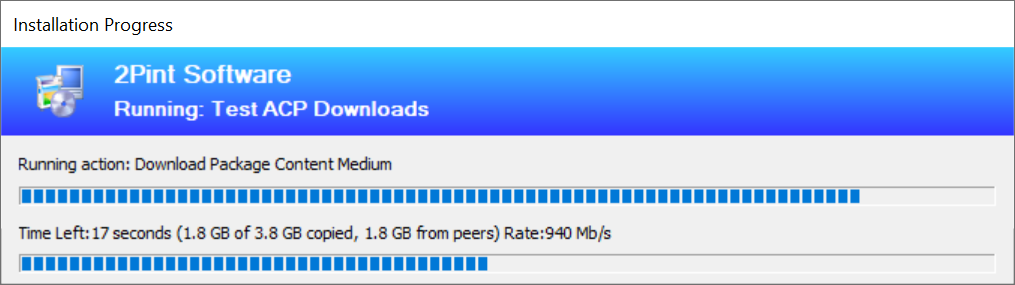
Second picture, from the host we were pulling from:
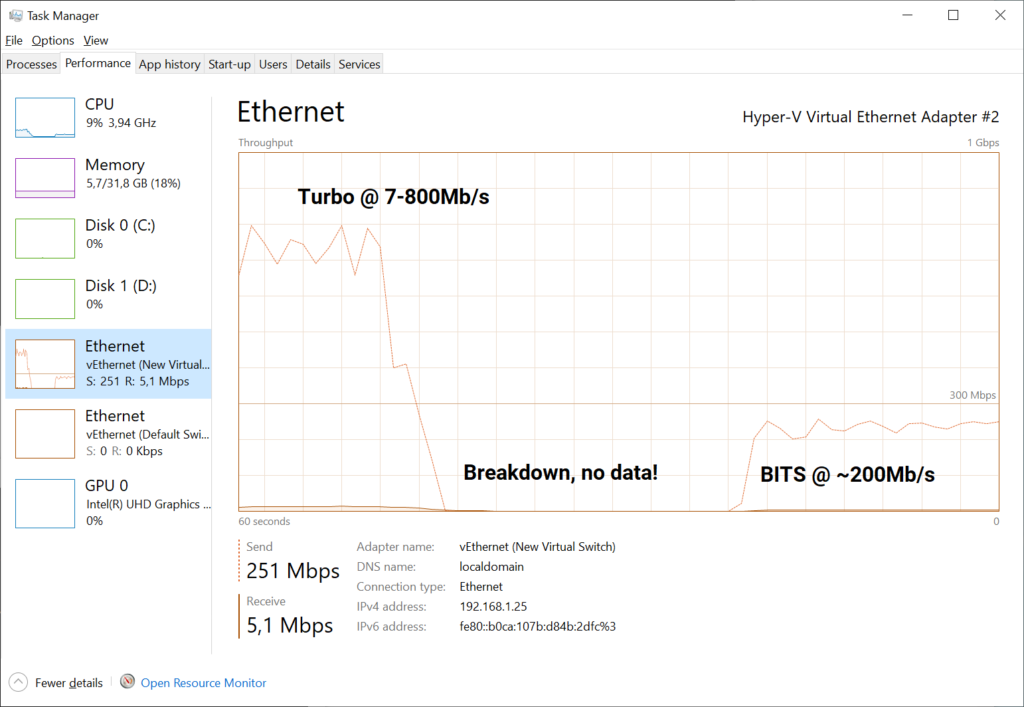
How do I disable it?
Remove the license key variable. We are looking to add in a "No Turbo" mode variable for easier control. There is also more control for this coming into a future version of StifleR.
'Nuff said, how do I get it?
You can sign up for a trial of the OSD Toolkit here: https://2pintsoftware.com/products/osd-toolkit/
If you trust that this is epic stuff - go ahead and request a quote and purchase support for the OSD Toolkit: https://2pintsoftware.com/pricing/
More Reading
How to choose the right compression algo for BranchCache packages: https://2pintsoftware.com/picking-the-right-compression-algorithm-for-branchcache/
Top Posts
2Pint Software blog roundup - spring 2026 edition
2Pint Software welcomes Nathan Ziehnert to the team!
2Pint Software welcomes Christian I. Nilsson to the team!

By David Meurer

By Andreas Hammarskjöld

By Andreas Hammarskjöld
By David Meurer